
The true value of Big Data analytics will be realised only when it acts as the unifying force that will take geospatial from the present state of a collection of building blocks to a self reliant discipline

Structured and unstructured data collected from diverse sources and used as an ensemble to derive information is referred to as Big Data. According to Wikipedia, Big Data consists of data sets that are so big that they cannot be handled efficiently by common database management systems. These data sets can range from tera to petabytes and beyond. In modern interconnected digital world, there are enormous real-time data streams from various sources, located in different servers. Mobile phones, credit cards, RFID devices, chatter on social networks, all create data streams which we may consider as ephemeral but which reside for years in unknown servers. When the occasion arises, these data streams can be accessed in a coordinated manner and analysed to yield information which would have otherwise remained hidden. For example, analysis of mobile phone records can establish the presence or absence of a person at a particular location. One of the most dramatic illustrations of Big Data and associated analytics is the tracing and capture of Osama Bin Laden in 2011.
According to Gartner, data is growing at about 59% a year globally. This growth is characterised by the four ‘V’s:
- Volume: The key drivers for the increase in data volumes within enterprise systems are transaction volumes and other traditional data types, as well as new types of data. Volume is not only a storage issue, but also a massive analysis issue.
- Variety: Apart from transactional information, now there are more types of information to analyse — structured and unstructured — mainly coming from social media and context-aware location-based mobile phones, databases, hierarchical data, documents, e-mail, metering data, video, still images, audio, stock ticker data, financial transactions, astronomy, atmospheric sciences, genomics, interdisciplinary scientific research such as biogeochemical research, military surveillance, medical records, and Big Science like the Giant Hadron Collider.
- Velocity: This involves creation of and access to streams of data, creation of structured records, and making them available for access and delivery. Velocity thus involves both matching the speed of data production and the speed of data processing to meet demand.
- Veracity: Professional managers are wary of unverified data. Since much of the data deluge comes from anonymous and unverified sources, it is necessary to establish and flag the quality of the data before it is included in any ensemble.
Geospatial Big Data sources
With the advent of satellite remote sensing, global navigation satellite systems (GNSS ), aerial surveys using photographic cameras, digital cameras, sensor networks, radar and LiDAR, the volume of geospatial data has grown exponentially with data production crossing storage capacity in 2007 itself. To these conventional sources add the unconventional sources like location-aware devices and you have a huge data stream.
In its report on Big Data, McKinsey Global Institute estimates that location data level stood at 1 petabyte in 2009 and had a growth rate of 20% a year. This did not include data from RFID sensors. It also does not include ‘dark data’, that is, data collected by researchers and lying in private archives. The UN-GGIM estimates that of the 2.5 quintillion bytes of data generated every day, a significant portion of the data is location aware.
However, it would be wrong to create bins for geospatial Big Data and other Big Data. The key to Big Data is the need to look at all data in ensembles specific to applications. Thus, according to Prof Shashi Shekhar of the University of Minnesota, Big Data also includes data-intensive computing, middleware, analytics and scientific and social applications.
In fact, the current trend of interconnecting different data sources through the Web will ultimately give rise to the Internet of Things where every source will have its own Uniform Resource Identifier and geospatial data will become omnipresent. There will be over 50 billion such resources by 2020.
Management of Big Data
The main problem with Big Data is that all data has become persistent. Data is duplicated and we create data pyramids for transmission ease. Further, there is a need to create and preserve the metadata, which in itself becomes a big task. Storage has become cheap but is unable to linearly scale up because of the growing volume of data. The immediate solutions are lossless data compression and abstraction of highresolution data; ways of compounding related geospatial data sets and eliminating duplication. Another solution is linked to data over the Web which consists of tuples of data sets which are contextualised, thereby adding value to the individual data sets.
The UN-GGIM has identified that techniques such as graphical processing units (GPU), parallel processing and databases like NoSQL (Not only SQL) will help to analyse Big Data in seconds instead of hours. Big Data streams are fast, typically 10-100 times faster than transactional data. In such situations it is difficult if not impossible to analyse data in real time with SQL. NoSQL essentially works to bring SQL interfaces to the runtime, thus probably eliminating the need for data warehouses; it does not mean that SQL and data warehouses will go away. According to IBM, data warehouses will still be around to store pre-processed data which is of high quality and has a broad purpose. On the other hand, Big Data repositories do not undergo such rigorous pre-processing and the stress is more on discovery rather than value. Repositories may also have different characteristics, some may stress atomicity, consistency, isolation and durability (ACID) while others may be more relaxed and operate on basic availability, soft state and eventually consistent (BASE) basis.
In this situation, Apache’s Hadoop suite of programmes provides an Open Source answer to handling of Big Data. Hadoop works in a batch processing mode and holds data till its utility is established through analytics. Such data can then be migrated to the warehouse. Hadoop can also act as an archiving service that moves archive-ready ‘old’ data from the warehouse to lower cost storage systems. Thus, traditional engines and the new data processing engines will continue to be needed. It is not a warehouse versus Hadoop or SQL versus NoSQL but both. Both IBM and Oracle have proprietary solutions built on Hadoop and NoSQL. Both systems use hardware and software solutions. The difference lies in the way they handle geospatial data. Oracle uses its geospatially enabled database while IBM makes geospatial analytics a part of its Netezza In-Database Analytics. While Hadoop is one solution there are other proprietary systems like Teradata which includes geospatial data handling in native formats.

Oracle Big Data Solution (Source: Oracle: Big Data for the Enterprise White Paper January 2012)
As in any typical Big Data application workflow, the Oracle Big Data Appliance (BDA) is used for filtering, transformation, extraction and other pre-processing operations on geospatial data, including raster imagery. High-volume, high-velocity data coming in from multiple sources such as sensors, satellites, mobile mapping, and location feeds from mobile devices, can be aggregated in the Oracle Big Data Appliance and processed to identify relevant high-value data. The Big Data Appliance is ideal for processing raw imagery and even applying specialised image processing like feature identification and tagging. This processed, transformed, highvalue data can be accessed directly from the BDA or integrated with other spatial data in a spatial database. Oracle provides high-speed Oracle Big Data Connectors that facilitates the transfer of data between the BDA and spatial database.
Grid and Cloud will play important parts in Big Data both in terms of providing the distributed platforms for data and analytics. Steven VanRoekel, US Chief Information Officer, says the combined initiatives to open up federal data, along with cloud computing, have the potential to create entire new industries. On the business front too there is considerable interest in Big Data in the Cloud. While some analysts opine that Big Data Analytics is ideally suited for the Cloud, others feel that the kind of load put on data storage by, say a Hadoop Cluster, would stress the performance of the storage infrastructure. There is a need to tweak Cloud architecture to improve the capacity, performance and agility of all Cloud services to provide better support for Big Data in the Cloud.
An example of such an integrated system combining advanced analytics and data storage in a Cloud infrastructure for geospatial intelligence analysts is the analytic Cloudbased system integrating NetApp data storage technology that is useful for both geospatial and analytic workloads and Data Tactic Corp’s expertise in data architecture and management, which provides advanced analytics tools for data extraction, resolution and link analysis as well as artifact-based search and geospatial capabilities. Another example is an integrated system for government agencies that need to capture, store, process and distribute massive volumes of intelligence and surveillance sensor data consisting of DataDirect Networks’ Web Object Scaler Cloud storage appliance integrated with YottaStor’s mobile computing and Big Data storage system called YottaDrive.
Big Data analytics
The key to Big Data is analytics. In a normal geospatial data setup, the analysis is a set of programmes, built in or written by a programmer which operates on a structured data set. What sets apart Big Data analytics is the need to analyse in addition unstructured and structured data streams in real time. These data streams can be 10 to 100 times the speed of transactional data. In geospatial context, these could be sensor data as well as field reports emanating from a disaster area or a battlefield.
Geospatial Big data analytics has been around for many years without it being termed as such. As an example, VanRoekel cites the opening up of geographic positioning systems data in the mid 1980s, which now is embedded in a range of commercial applications. “As a free open data stream, we almost overnight created $100 billion in value to the marketplace,” he says. He also noted how the US Weather Service, first launched in the Smithsonian Institute, provided an Open Source approach to collection and reporting of weather data from across the country — another amazing “big data stream.”
Carson J.Q. Farmer et al in the proceedings of GIScience in Big Data Age writes that geospatial analytics in big data requires “new approaches that are flexible, non-parametric, computationally efficient and able to provide interpretable results for modelling dynamic and non-linear processes in data rich situations”. Till now geospatial Big Data analytics has focussed on data visualisation and descriptive analysis. GIScience needs to move away from this approach and move on to a model-centric approach, which stresses the underlying spatial processes rather than addressing the data bottleneck. According to IDC, storage capabilities have been surpassed by data stream volumes as early as 2007 and there is no way this can be bridged. The need is for runtime stream data analysis. The focus therefore shifts from the database to a model dictionary that is applied to streaming data to detect the states of the environment to highlight normal and abnormal conditions. Stream processing can be used to tune model parameters and to store useful data samples.
This is what a combination of NoSQL and Hadoop can do, as illustrated by the IBM model of the Netezza analytics platform and Oracle’s Integrated Software Solutions Stack.

Oracle Integrate Software Solution Stack
Compute intensive operations such as image processing of high resolution satellite imagery can be performed in parallel on the Oracle Big Data Appliance. Multiple systems can be cabled together for very large Hadoop clusters for processing massive numbers of images in parallel. The high-speed connection between Oracle Big Data Appliance and Oracle Exadata (via infiniBand) enables geospatial applications to use the appropriate platform (batch processing and preprocessing vs. transactional) for a given task.
Another common use case is extraction of location-related semantics from unstructured documents. Many types of social media are highly unstructured and riddled with ambiguous terms. Nevertheless, it commonly refers to important concepts like names, places, times, etc. While human readers might be able to infer and reconcile these ambiguities, machines cannot — at least not without some form of pre-processing. Applying natural language processing (NLP) on unstructured media enables developers to generate semantic indexes of terms from these sources. This “structuring” process reduces the ambiguity of social media and enables linking with more conventional structured relational content commonly found in spatial databases and GIS. This type of social media analysis is now becoming common place, and is increasingly referred to as “social media analytics” or Big Data analytics and is one of the more exciting aspects of geospatial computing.
Big Data use cases
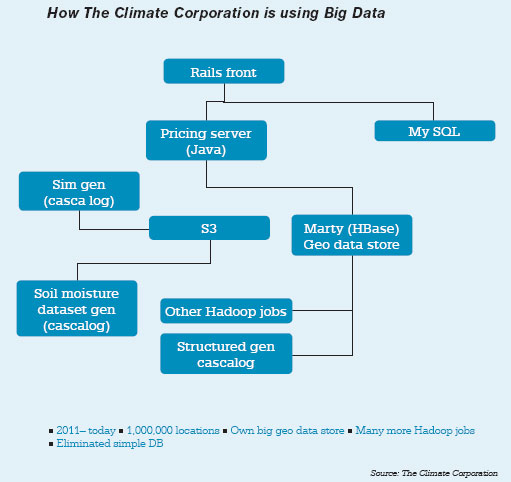
- The Climate Corporation, an insurance company, is using Big Data to deal with the planet’s toughest challenge: analysing the weather’s complex and multi-layered behaviour to help the world’s farmers adapt to climate change. By combining modern Big Data techniques, climatology and agronomics, The Climate Corporation protects the $3-trillion global agriculture industry with automated hyper-local weather insurance. The data is primarily georeferenced time series data and the company uses its proprietary geo-data store, called Marty. This is built on HBase and provides a couple of abstractions: geo-indexing and querying of data using R trees, and generic JSON document storage and indexing. The data process is depicted in the diagram on left.
- McLaren’s Formula One racing team uses Big Data to identify issues with its racing cars using predictive analytics and takes corrective actions pro-actively before it’s too late. The team spends 5% of its budget on telemetry. Its modern F1 car is fitted with about 130 sensors. In addition to the engine sensors, video and GPS is used to work out the best line to take through each bend. Their cars generate gigabits of data every weekend, which is analysed in real time to make decisions. The sensor data is helping in traffic smoothing, energy-optimising analysis and driver’s direction determination. McLaren’s proprietary software analyse all sensor data and helps the team cut costs and enables the governing body — the FIA — to more easily detect banned devices. For example, new Pirelli tyres this year meant teams had to watch for tyre wear, grip, temperature under different weather conditions and tracks, relating all that to driver acceleration, braking and steering.
- Working with IBM, Vestas Wind Systems A/S (VWS) is implementing a big data solution that is significantly reducing data processing time and helping staff more quickly and accurately predict weather patterns at potential sites to increase turbine energy production. Data currently stored in its wind library comprises nearly 2.8 petabytes and includes more than 178 parameters, such as temperature, barometric pressure, humidity, precipitation, wind direction and wind velocity from the ground level up to 300 feet, along with the company’s own recorded historical data. Future additions for use in predictions include global deforestation metrics, satellite images, historical metrics, geospatial data and data on phases of the moon and tides. The IBM InfoSphere BigInsights software running on an IBM System x iDataPlex system serves as the core infrastructure to help Vestas manage and analyse weather and location data in ways that were not previously possible. For example, the company can reduce the base resolution of its wind data grids from a 27×27 kilometer area down to a 3×3 kilometer area — a nearly 90% reduction that gives executives more immediate insight into potential locations.
- US Xpress, provider of a wide variety of transportation solutions, collects about a thousand data elements ranging from fuel usage to tyre condition to truck engine operations to GPS information, and uses this for optimal fleet management and to drive productivity, saving millions of dollars in operating costs. US Xpress is using several Informatica tools, including IDQ for data quality; PowerExchange, which talks to its AS/400 systems; and CPE for real-time data monitoring, among others. When an order is dispatched, it is tracked using an in-cab system installed on a DriverTech tablet. US Xpress constantly connects to the devices to monitor progress of the lorry. The video camera on the device could be used to check if the driver is nodding off. There is also a speech recognition capability, which is more intuitive and easier to use for the driver, compared to the tablet’s touch UI. All the data collected from the DriverTech system is analysed in real time at the US Xpress operations centre. This is achieved by using geospatial data, integrated with driver data and truck telematics. By using this information, operations can minimise delays and ensure trucks are not left waiting when they arrive at a depot for maintenance.
- With an aim to bring the world to the third phase of mobility, Nokia needed to find a technology solution that would support the collection, storage and analysis of virtually unlimited data types and volumes. Effective collection and use of data has become central to Nokia’s ability to understand and improve user experiences with phones and other location products. The company leverages data processing and complex analyses in order to build maps with predictive traffic and layered elevation models, to source information about points of interest around the world, to understand the quality of phones and more. To grow and support its extensive use of Big Data, Nokia relies on a technology ecosystem that includes a Teradata enterprise data warehouse (EDW), numerous Oracle and MySQL data marts, visualisation technologies, and at its core: Hadoop. Nokia has over 100 terabytes of structured data on Teradata and petabytes of multi-structured data on the Hadoop Distributed File System. Because Hadoop uses commodity hardware, the cost per terabyte of storage is on an average 10 times cheaper than a traditional relational data warehouse system.
Business opportunities
Big Data analytics is an attractive field. According to analysts Big Data market is expected to reach $48.3 billion by 2018. As the ‘use cases’ show, it can range over a wide area of applications. There are very good commercial and Open Source tools available as well as opportunities to develop new tools specific to applications. This is an opportunity for software developers. However, the real challenge is in concentrating on higher level problems and developing integrated solutions to provide intelligence required by different domains.
Capacity requirements
Effective use of Big Data will need geospatial analysts of a different kind. They can be mathematicians, computer programmers, geographers, engineers, social scientists or business managers with ability to ‘think out of the box’ and look at processes like spatial interactions, spatial behaviour and spatial diffusion along with traditional geospatial techniques and create models which can work on streaming and static Big Data. These capabilities cannot be taught in classrooms but need to be encouraged through real life practices.

Research areas
Dawn Wright, Esri’s Chief Scientist, had this takeaway from GIScience 2012: “Academics tend to think in terms of questions. Among the many questions they seem very interested in at the moment are:
- What new fundamental problems does big data pose to GIScience?
- How can we best foster and synergise research on big data across pertinent research communities?
- What are the significant kinds of big data from a spatial perspective? Why do they matter?
- What are the challenging issues of modeling uncertainty in big data?
- How can we best prepare students in the use, development of, and analysis of big data?
In response to these and other questions, a number of research areas are being pursued, including:
- Most GIScience algorithms need to be rewritten to fit the new infrastructure of Big Data.
- Various communities — such as the machine learning and complex process modelling communities — need to talk to each other and work together.
- We have succeeded in getting metadata to talk to data. We now need models talking to data, models talking to other models, and models talking to us via effective workflows.
The Panel on Big Data in GIScience held earlier at UCSB on February 2012 also identified the following research areas:
- Semantic approaches to support machine processing of data
- Big Data knowledge extraction through ontology mapping
- Integrating data across vocabularies
- Mining data to discover rules about the data that can then be implemented in computational systems
GIScience research has to move beyond data storage, handling and mining issues and concentrate on modelling to understand the underlying spatial processes, particularly dynamic spatial processes.
The future
Big Data is no stranger to the geospatial world; only it is known by several names. Perhaps Big Data is a way of defining a paradigm shift to a data-intensive collaboration where processes reinforce traditional database approaches. There is a considerable amount of hype which will ultimately lead to a degree of disillusionment. Then the hard work will follow before the true value of Big Data analytics is realised. Ultimately Big Data will act as the unifying force which will take geospatial from the present state of a collection of building blocks to a self-reliant discipline.
(The author is grateful to Sunil M.K., Head of AEC Division India, Autodesk; Xavier Lopez, Director of Oracle’s Spatial, Location and Network technologies group, Hiren Bhatt, his old student and now friend, and colleague Anand Kashyap for providing valuable inputs to this article.)


